AIトレーニングデータの作り方と社内ガバナンス設計
AIトレーニングデータの作り方と社内ガバナンス設計
社内データをAI学習に使う話は、モデル選定より前にデータの作り方と運用の回し方を同時に決めないと、現場で止まります。DX推進の現場では、評価データの汚染、重複の多さ、ラベル基準の不統一が後工程で効いてきて、学習よりも再整備に時間を取られるケースが繰り返し発生しています。
社内データをAI学習に使う話は、モデル選定より前にデータの作り方と運用の回し方を同時に決めないと、現場で止まります。
DX推進の現場では、評価データの汚染、重複の多さ、ラベル基準の不統一が後工程で効いてきて、学習よりも再整備に時間を取られるケースが繰り返し発生しています。
IBMが整理するように、トレーニングデータはモデル性能を左右する土台であり、実務では準備と前処理に開発工数の8割超が乗ることも珍しくありません。
この記事は、営業DXや業務AIの導入を担う実務者に向けて、個人情報の判断軸、品質KPI、RACI風の役割設計、PoCと本番の差分までを、法務確認につなげやすい形で6ステップに落とし込みます。
要するに、社内データ活用は「集めれば進む」ではなく、「どのデータを、どの基準で、誰の責任で回すか」が先です。
『政府広報オンライン』や『Google Cloud』が示す考え方を土台に、一般論で終わらない設計の型を整理します。
AIトレーニングデータとは何か
定義と用語の整理
AIトレーニングデータとは、機械学習モデルが入力と出力の関係、あるいはデータ内の構造や傾向を学ぶために使うデータです。
IBMが整理するように、教師あり学習では正解付きのデータを使い、モデルはその対応関係から予測ルールを学びます。
要するに、モデルの振る舞いはアルゴリズムだけでなく、何を見せて学ばせたかで決まります。
実務で押さえたい構成要素は、特徴量、ラベル、メタデータの3つです。
特徴量はモデルが判断材料として受け取る入力で、営業FAQボットなら問い合わせ本文、件名、カテゴリ、流入チャネル、過去の会話文脈などが該当します。
ラベルは学習させたい正解で、たとえば「請求」「解約」「操作方法」といった問い合わせ種別や、「回答候補Aが適切」といった判定結果です。
メタデータは作成日時、担当部署、言語、取得元、アノテーター、版管理情報のような周辺情報で、学習そのものだけでなく品質管理や再現性の確保に効いてきます。
このラベルを付ける作業がアノテーションです。
画像なら物体に枠を引く、音声なら発話区間を書き起こす、テキストなら意図分類や感情分類を付ける、といった形になります。
業務データでは、ここが最初のつまずきどころになりがちです。
同じ「解約相談」でも、即時解約の依頼を指すのか、料金見直しの相談まで含めるのかで判断が割れます。
そこで実務では、先にルーブリック、つまり判定基準の文書を作り、曖昧な境界例を定義してからラベル付けに入る流れが有効です。
さらに、同じデータを別の担当者が独立にラベル付けするダブルアノテーションを入れると、基準の穴が見えます。
そこで食い違ったケースを合意形成の場で見直すと、ラベルの再現性が上がります。
学習パラダイムごとの違いは、次の図で捉えると整理しやすくなります。 学習パラダイムごとの違いは、下の表で整理するとわかりやすくなります。
| 学習パラダイム | 使うデータ | 何を学ぶか | 営業・業務AIの例 |
|---|---|---|---|
| 教師なし学習 | 特徴量のみ | データのまとまりや構造を抽出する | 顧客セグメント分割、FAQクラスタリング |
| 半教師あり学習 | 一部ラベル付き + 多数の未ラベル | 少量の正解で全体の構造を活用 | 限られた分類済みログでの問い合わせ分類 |
| 強化学習 | 状態・行動・報酬 | 試行錯誤で報酬が高い行動方針 | 対話エージェントの応答最適化 |
どの方式でも共通するのは、データの癖がそのままモデルに移ることです。
偏ったサンプル、不正確なラベル、重複の多いレコードを混ぜると、精度だけでなく公平性や運用時の安定性まで崩れます。
トレーニングデータは「量が多ければよい」ではなく、「目的に合う形で整っているか」が先に問われます。
学習パラダイムの違い
教師あり学習は、業務システムと最も接続しやすい方式です。
SFAやCRMに蓄積された履歴に対して、「失注理由」「次回アクション要否」「問い合わせ分類」のようなラベルが付いていれば、その関係を学習できます。
営業DXの文脈でAIが現場に乗りやすいのは、このラベルが業務プロセスに埋め込まれているからです。
一方で、業務システム上の入力ルールが揺れていると、ラベル品質もそのまま揺れます。
商談ステータスの運用が部署ごとに違う環境で受注確度モデルを作ると、モデル以前に正解定義が崩れます。
教師なし学習は、まだ整理されていないログや会話データの把握に向いています。
営業FAQの問い合わせ履歴を眺めると、現場の感覚では「料金」「操作」「契約」で分かれているつもりでも、実データでは「請求書再発行」「権限設定」「プラン変更」が混ざり、粒度が揃っていないことがよくあります。
こうしたときにクラスタリングや埋め込み表現を使うと、先にデータの塊が見えます。
その結果をもとにラベル体系を作ると、あとから教師あり学習へつなげやすくなります。
半教師あり学習は、現場でラベル付けの工数が足りないときの現実解です。
たとえば数万件の問い合わせログがあっても、全件に人手でラベルを付けるのは重い作業です。
少数の高品質なラベル付きデータと、大量の未ラベルデータを組み合わせることで、ラベル作成コストを抑えながら性能を引き上げる発想です。
ただし、この方式は「少数のラベルが正しいこと」が前提になるので、最初のアノテーション設計を雑にすると土台が傾きます。
学習・検証・テストの分割と独立性
トレーニングデータは、一般に学習用、検証用、テスト用に分けて扱います。
Ultralyticsが示す目安では、学習用に全体の70〜80%を充てる構成がよく使われます。
営業FAQボット用に問い合わせログを整理したとき、この独立性が崩れると評価が一気に甘くなる感覚を何度も見てきました。
たとえば同じ顧客企業から短時間に連続で送られた問い合わせは、文面がよく似ます。
件名だけ少し違って本文がほぼ同じ、担当者名だけ差し替わっている、返信の引用が残っている、といったケースです。
これを何も考えずランダム分割すると、学習用に入った文面の兄弟データがテスト用にも混ざります。
するとモデルは本当に汎化したのではなく、似た文章を見た記憶で当てているだけなのに、数値上は高精度に見えます。
現場投入後に精度が落ちる原因の多くは、アルゴリズムの選定より先に、この分割設計にあります。
ℹ️ Note
学習・検証・テストの分割は、レコード単位ではなく「似たデータの固まり」を意識すると評価の過大化リスクが下がります。
顧客、案件、会話スレッド、期間のどれが独立単位になるかを先に決めることが有効です。
検証用とテスト用を混同しないことにも注目したいポイントがあります。
ハイパーパラメータの調整や特徴量の追加をテスト結果を見ながら繰り返すと、テストデータが事実上の学習材料になります。
その瞬間に、最終評価の客観性が失われます。
PoCではこの線引きが曖昧になりやすく、少ないデータで何度も試しているうちに、気づかないままテストデータに最適化してしまいます。
評価用のデータは「正解を知っているが触らない領域」として隔離しておくほうが、後工程で揉めません。
この分割設計は、アノテーション運用ともつながっています。
ルーブリックが途中で変わったのに、旧基準のラベルと新基準のラベルが同じ評価セットに混ざると、モデルではなく評価基準の揺れを測ることになります。
ダブルアノテーションで不一致が多い項目は、モデル改善より先に基準の再定義が必要です。
データセットは単なる材料ではなく、学習、評価、運用をつなぐ設計物です。
その認識があるかどうかで、PoCの見栄えと本番精度のギャップが変わります。
なぜ今、トレーニングデータの社内ガバナンスが重要なのか
市場規模と投資の現実
トレーニングデータの社内ガバナンスが今問われる背景には、AI活用が実験段階から実装段階へ移っていることがあります。
PoCでは「まず精度が出るか」を見ますが、本番では「そのデータを継続利用できるか」「権利関係を説明できるか」「監査に耐えるか」が先に問われます。
営業DX案件でも、PoC後に本番移行を断念したケースを振り返ると、モデル精度よりも、使ったデータの由来や利用許諾が曖昧だったことが止まる理由になりがちです。
初期段階からデータ台帳と承認フローを持っていないと、後から法務確認を足す形になり、現場の期待値と管理部門の判断が噛み合わなくなります。
市場の伸びも、この論点を後回しにできない理由です。
AIトレーニングデータセット市場は、Fortune Business Insightsの推計では2024年に292億米ドル、2025年に350億米ドル、2032年に1,704億米ドルへ拡大するとされています。
一方で、別調査では2025年31億9,000万米ドル、2026年38億7,000万米ドルという推計もあり、調査会社によって規模に大きな差があります。
ここは市場予測の数字そのものより、定義や対象範囲が調査ごとに異なるほど、関連投資が急速に広がっている点を見るべきでしょう。
要するに、正確な市場規模を1つに固定することより、社内で扱うデータの統制レベルを拡張可能な形で整えておく方が、経営判断としては再現性があります。
B2B企業の実装フェーズでは、データ量だけでは差がつきません。
たとえば問い合わせ分類や提案文生成では、1クラスあたり少なくとも1,000サンプルが1つの目安になる一方、同じ1,000件でもラベル基準が揺れていれば学習効果は落ちます。
必要になるのは、既存のデータガバナンスをAI学習向けに拡張する視点です。
Google Cloudが整理するように、データガバナンスは収集、保存、処理、利用、廃棄までを含む全社的な枠組みです。
AI活用ではこの枠組みに、学習利用の可否、ラベル定義、データソースの権利、評価用データの独立性といった要件を追加しなければ、本番運用の入口で止まります。
規制・ガイドラインの動向
市場拡大と並行して、規制やガイドラインの論点も具体化しています。
日本の個人情報保護法では、個人情報は生存する個人に関する情報で、単独または容易照合によって個人を識別できる情報を含みます。
氏名やメールアドレスだけでなく、他の情報と組み合わせて本人特定に至るデータも対象になり得ます。
学習用データでは、CRMの属性情報、商談履歴、問い合わせログ、音声文字起こしなどが複合的に結びつくため、現場感覚より法的な射程が広くなりやすい領域です。
この前提で見ると、AI学習データの扱いは単なる情報管理では済みません。
個人データの漏えいなど、本人の権利利益を害するおそれが大きい事案では、個人情報保護委員会への報告や本人通知が必要になります。
つまり、学習前のデータ抽出や加工の段階でアクセス制御、利用目的、加工履歴、持ち出し経路を追えない状態は、精度以前に運用リスクを抱えていることになります。
匿名加工情報や仮名加工情報の活用は有力な選択肢ですが、元データ台帳、加工ルール、識別子の分離管理がなければ説明責任を果たせません。
国内でも、AIガバナンスの議論はデータガバナンスと接続する形で進んでいます。
EU域外にも影響が及ぶため、EUの規制動向は参照されますが、施行時期や細部の要件は更新されることがあるため、最新の公式公表(EU の公式サイト等)を確認してください。
実務的には、リスク分類や透明性、ガバナンス体制に関する要件が強化される方向で議論が進んでいる点を押さえておくとよいでしょう。
国内でも、AIガバナンスの議論はデータガバナンスと接続する形で進んでいます。
経済産業省のAI原則実践のためのガバナンス・ガイドラインは、組織としての管理体制、説明責任、リスク対応を整理する土台になりますし、デジタル庁でもデータガバナンス指針の整備が進んでいます。
NTT DATAがAIアドバイザリーボードを設置して社内外のガバナンス整備を進めているのも、AI単体ではなくデータ管理と接続しないと運用が回らないからです。
加えて、リスク・コンプライアンス担当者の83%が規制順守を極めて重要と答えた調査結果もあり、AI活用が情報システム部門だけのテーマではなく、法務、セキュリティ、事業部門を巻き込む経営課題へ移っていることが見て取れます。
「個人情報保護法」を分かりやすく解説。個人情報の取扱いルールとは? | 政府広報オンライン
個人情報とは生存する個人に関する情報で、特定の個人を識別できる情報です。個人情報保護法上、具体的にどのような情報が個人情報になるのか、その取扱いのルールや漏えいが発生したときの対処について解説します。
www.gov-online.go.jp“整備だけでは足りない”理由
ここでいう「整備」とは、データを集めて、欠損を埋めて、形式をそろえるところまでを指すことが多いはずです。
もちろんそれ自体は必要ですが、AI学習ではそれだけでは止まります。
理由は、学習データに求められる管理項目が、一般的な分析用データより一段深いからです。
どこから取得したのか、誰が利用許諾を判断したのか、個人情報や機密情報をどう加工したのか、ラベルは誰がどの基準で付けたのか、どの版のデータでどのモデルを学習したのか。
こうした履歴が残っていないと、精度が出ても再学習も監査対応もできません。
データプロベナンスの考え方が重視されるのもこのためです。
標準案では、データソース、法的権利、プライバシー保護、生成方法、用途制限などの記録が中核に置かれています。
要するに、学習データはファイル保管の問題ではなく、由来を説明できる状態で流通させる運用が必要です。
営業DXの現場でPoC後に失速する案件の多くも、最初はCSVがそろっていたのに、本番審査の段階で「このログは何の同意に基づくのか」「外部委託先が付けたラベルの基準は何か」が説明できず止まる流れです。
データ整備を進めたつもりでも、権利と責任の整理が空白のままだと、本番では資産ではなく負債になります。
この不足を埋めるには、既存のデータガバナンスをAI向けに拡張する発想が欠かせません。
たとえばマスターデータ管理やBI向けの品質管理で運用していたルールに、AI学習用途の承認区分、匿名加工・仮名加工の判断基準、評価データの分離ルール、ラベル変更時の版管理を足す形です。
組織設計も同様で、中央集権型だけでは現場のスピードに追いつかず、分散型だけでは品質と監査対応がぶれます。
中堅企業では、共通基準は中央で持ちつつ、現場部門がデータ候補の一次管理を担うハイブリッド型が現実的な落としどころになりやすいと言えます。
合成データや匿名加工データの活用も選択肢ですが、ここでも「整備したから安全」とは言えません。
UNUの『合成データ利用に関する提言』が示す通り、合成データはデータ不足やプライバシー対策に有効な一方、元データの偏りを引き継いだり、生成プロセスが不透明だったりすると、別の形で説明責任が重くなります。
実データ、匿名加工・仮名加工データ、合成データのどれを選んでも、必要なのは「使ったデータの履歴をたどれること」です。
つまり、これから求められる社内ガバナンスは、データを整える作業ではなく、AI実装フェーズで止まらないように、既存の全社ガバナンスを学習データ運用まで伸ばす設計だと考えられます。

Recommendations on the Use of Synthetic Data to Train AI Models
unu.eduAIトレーニングデータの作り方【実務6ステップ】
AIトレーニングデータの整備は、思いついた順に始めるとほぼ確実に手戻りが出ます。
IBMの『トレーニング・データとは』が整理するように、学習データはモデル性能の土台ですが、実務では性能だけでなく、利用可能性、権利、監査性までセットで設計しないと本番運用に乗りません。
要するに、データ作成は「集める作業」ではなく、「業務要件とガバナンスを満たす形に変える作業」です。
営業・マーケティング領域のAI導入で止まりにくい進め方を、6ステップで整理します。
ステップ1: 課題定義と成功指標
出発点はモデルではなく業務KPIです。
たとえば営業日報の要約AIなら、問うべきは「どのモデルを使うか」よりも、「要約で何分短縮したいのか」「読後に案件状況を誤解しないか」「個人名や取引先情報をどこまで残すのか」です。
ここが曖昧なままデータを集め始めると、あとから法務、情報セキュリティ、事業部で見ているゴールがずれて、同じデータでも使える・使えないの判断が割れます。
この段階では、少なくとも4点を文書化します。
ひとつは業務上の目的です。
分類、要約、検索強化、レコメンドのどれなのかで必要なデータ形式も評価軸も変わります。
次に成功指標です。
モデル精度だけでなく、業務KPIとの接続が必要です。
要約AIならROUGEや人手評価だけでなく、レビュー時間短縮や修正回数の減少まで見ないと、導入効果を判断できません。
3つ目は制約条件で、個人情報、著作権、契約上の利用範囲、持ち出し可否をここで定義します。
4つ目は責任分担です。
RACIのような形で、誰が収集責任を持ち、誰が最終承認し、誰に事前相談するかを先に固定すると、承認待ちで止まる場面が減ります。
成果物としては、A4数ページでもよいので課題定義書を作っておくと、その後の棚卸しやアノテーションの軸がぶれません。
記載項目は「対象業務」「モデルの役割」「成功指標」「除外すべきデータ」「法務・セキュリティ制約」「責任者」です。
目安期間は、既存業務が整理されているテーマなら短期間、複数部門にまたがるテーマでも数週間でたたき台までは作れます。
ステップ2: データ棚卸し・台帳
課題が定まったら、次は「使えそうなデータ」ではなく「使ってよい根拠があるデータ」を洗い出します。
ここで必要なのがデータ台帳です。
対象はSFA、CRM、MA、FAQシステム、問い合わせログ、営業日報、議事録、ナレッジベース、外部購入データまで含みますが、一覧にするときの軸をそろえることが肝になります。
台帳には、少なくともデータソース、作成部門、取得経路、権利状態、個人情報の有無、要配慮情報の有無、機密区分、用途制限、保管場所、更新頻度、利用承認者、データプロベナンスを入れます。
前のセクションで触れた通り、AI向けでは「どこにあるか」だけでは足りません。
どの同意や契約に基づいて取得したのか、第三者提供の制約があるのか、加工前後の版を追えるのかまで残しておかないと、学習後に説明ができなくなります。
中堅企業の現場では、中央集権ですべての台帳更新を握ると現場の速度が落ち、分散型に寄せると項目定義が崩れます。
そのため、共通フォーマットは中央で持ち、一次入力は各部門が担うハイブリッド型が収まりやすい設計です。
『Google Cloudのデータガバナンス解説』でも、ポリシーだけでなく役割と運用の整合が前提に置かれていますが、AI用の台帳ではそれをさらに細かくするイメージです。
成果物はデータ台帳です。
最低限の列を固定しておけば、後工程で「このログは外部委託先に渡せるか」「評価データ候補として隔離できるか」を即座に判断できます。
目安期間は、対象範囲が1業務なら比較的短く、全社横断なら段階的に広げるのが現実的です。
データ ガバナンスとは | Google Cloud
データ ガバナンスは、データの安全性、正確性、可用性を確保するための取り組みです。このプロセスでデータの品質と管理をどのように改善できるかをご覧ください。
cloud.google.comステップ3: 個人情報・権利の確認と加工選択
棚卸しの次に来るのが、個人情報と権利の確認です。
ここは「名前を消せば終わり」ではありません。
『個人情報保護委員会』が示す匿名加工情報や仮名加工情報の考え方でも、再識別されないこと、あるいは識別子を分離管理して統制することが前提になります。
営業・マーケティングのデータは、氏名やメールアドレスだけでなく、所属、役職、地域、案件履歴、行動ログの組み合わせで個人が浮かびやすいので、単純マスキングでは足りない場面が出ます。
ここで決めるのは、実データをそのまま使うのか、仮名加工にするのか、匿名加工に寄せるのか、あるいは対象から除外するのかという選択基準です。
社内で改善サイクルを回す用途なら、識別符号を別管理した仮名加工データが現実的なことがあります。
外部アノテータや外部学習基盤に出すなら、匿名加工か除外の判断が中心になります。
著作権や契約上の利用制限も同じで、FAQ原稿、提案書、外部記事、取引先資料などは、社内に保存されているだけで学習転用まで許されるとは限りません。
実務では、加工方式そのものより選定理由を残すことが効きます。
なぜ匿名加工ではなく仮名加工なのか、なぜこの属性は削除し、この属性は年代化や地域集約で残すのかを記録しておくと、後から監査や再学習時に判断を再利用できます。
年齢、性別、地域のような準識別子が複合すると再識別の余地が残るため、削除、集約、カテゴリ化、必要に応じたサンプリングやノイズ付与まで含めて考えるのが実務寄りです。
成果物は、データ台帳にひもづく加工方針シート、または課題定義書の別紙でも構いません。
項目は「該当する個人情報」「権利確認結果」「加工方式」「除外基準」「識別子の保管責任者」です。
目安期間は、法務レビューを含むため、前段の棚卸しよりも関係者調整に時間を使う工程になります。
個人情報保護委員会 - PPC |個人情報保護委員会
www.ppc.go.jpステップ4: 前処理・アノテーション運用
加工方針が固まったら、ようやく学習に向けた前処理とラベル付けに入ります。
この工程は単なる整形ではなく、モデルの振る舞いを決める設計作業です。
重複排除、表記揺れの正規化、欠損処理、形式統一、ノイズ除去、チャンク分割のルールをそろえないと、同じ内容が別レコードとして学習されたり、逆に重要な差分がつぶれたりします。
営業日報の要約AIを扱ったときも、派手な特徴量追加より先に、ほぼ同一内容の重複を落とし、顧客名や商談フェーズの表記揺れを正規化しただけで、評価指標のぶれが落ち着いたことがあります。
現場では新しいモデルやプロンプトに目が向きがちですが、入力データのゆがみを減らすほうが先に効く場面は珍しくありません。
要するに、モデル改善に見える課題の一部は、前処理の未整備で起きています。
アノテーションでは、まずアノテ基準書を作ります。
分類ならラベル定義、境界事例、優先ルール、迷ったときの判断順序を明文化します。
要約評価なら「何が含まれていれば正か」「冗長表現はどこまで許容するか」を定めます。
ここが1ページの口頭メモだと、人が増えた瞬間にラベルが割れます。
実務では、少量の試験ラベルを付けて基準書を更新し、その後に本番ラベリングへ入る流れが安定します。
運用面では、ダブルチェックかサンプル監査を組み込みます。
内製なら業務知識を反映しやすい一方、担当者ごとの差が出やすいので、判定が割れたケースを基準書へ戻す仕組みが必要です。
外部委託なら秘密保持契約だけで終わらせず、作業環境、再委託可否、持ち出し制限、監査手順まで含めて設計します。
e-Wordsの『教師データの解説』が示す通り、教師あり学習ではラベル品質がそのまま学習品質になりますが、現場では「誰がどの基準で付けたか」まで残して初めて再現可能になります。
成果物はアノテ基準書と、前処理ルールを記したデータ加工仕様です。
目安期間は、基準書の初版作成と試験運用に一定の時間を見込む必要があります。
ここを急いで本番投入すると、あとから全件修正のコストが跳ね返ります。
教師データ(トレーニングデータ / 訓練データ)とは - IT用語辞典 e-Words
教師データ(トレーニングデータ、訓練データ)とは、機械学習で学習に用いるデータセットのうち、「例題」と「正解」を対応付けた形式に整理されたデータ。学習プロセスによって、例題を入力すると正解を出力するようにモデル内のパラメータを更新する。対象
e-words.jpステップ5: 品質評価とデータ分割
ここで見逃せないのが、評価データの独立確保です。
FAQボットの案件では、PoCの段階で評価用データを先に隔離しておいたことで、学習データの追加やルール変更をしても、どこまで改善したのかを一貫した基準で見られました。
この“隔離確保”をしていないと、PoC中に都合のよいデータが評価側へ混ざり、精度が上がったのか、評価が甘くなったのか分からなくなります。
本番移行の会議で判断が割れるケースは、モデル性能そのものより、評価セットの独立性が崩れていることが原因になりがちです。
💡 Tip
品質レポートは、精度指標だけでなく「どのデータを除外したか」「どのラベルで不一致が多かったか」まで残すと、次の再学習で同じ議論を繰り返さずに済みます。
成果物は品質レポートです。
中身は、品質指標、分布確認、除外件数、ラベル一致率、分割方針、評価データの保管場所と承認者です。
目安期間は、初回構築時にやや重くなりますが、テンプレート化すると2回目以降は速くなります。
ステップ6: 運用モニタリングと再学習
学習データ作成は、モデル公開で終わりません。
営業現場の入力ルール、FAQの表現、商品体系、法務要件が変われば、学習時には正しかったデータも徐々に古くなります。
そのため、本番後は推論結果だけでなく、入力分布、ラベル分布、エラー傾向、手修正率を継続監視し、ドリフトを検知する仕組みが必要です。
ここでの論点は「再学習するかどうか」だけでなく、「どの条件を満たしたら再学習を申請できるか」です。
再学習は、現場からの要望だけで回すと統制が崩れます。
新規データの追加元、権利状態、個人情報の加工状況、評価データへの影響、品質レポートの差分を確認する承認ゲートを置くことで、改善と監査の両方を回せます。
RACIでAccountableを明確にしておくと、再学習可否の判断が止まりません。
加えて、どの版のデータでどのモデルを作ったか、削除依頼や保管期限にどう対応したか、誰がアクセスしたかを監査ログとして残します。
削除・保管ルールもこの段階で効いてきます。
学習済みモデルに影響する元データをどこまで保持するのか、仮名加工データの識別子対応表を誰が管理するのか、外部委託先の作業データをいつ消すのかを定めておかないと、再現性とコンプライアンスの両方が崩れます。
『SAPのデータガバナンス解説』でも、ポリシーだけでなく手順と責任分担が一体で扱われていますが、AI運用ではそこに版管理と再学習承認を足す必要があります。
成果物は再学習申請書、監査ログ仕様、削除・保管ルールです。
申請書には、再学習理由、追加データの由来、加工状況、品質差分、評価結果、承認者を入れます。
目安期間は、初回に承認フローを組んでしまえば、その後は定例運用へ落とし込めます。
運用フェーズで止まらないチームは、モデルの更新頻度よりも、更新してよい条件を文書化しているチームです。

データガバナンスとは何かメリットとベストプラクティス | SAP
データガバナンスとは、ポリシー、プロセス、テクノロジーツールについて述べたものです。データガバナンスによって、企業データの正確性、安全性、エンドユーザーからのアクセス性が確保されます。
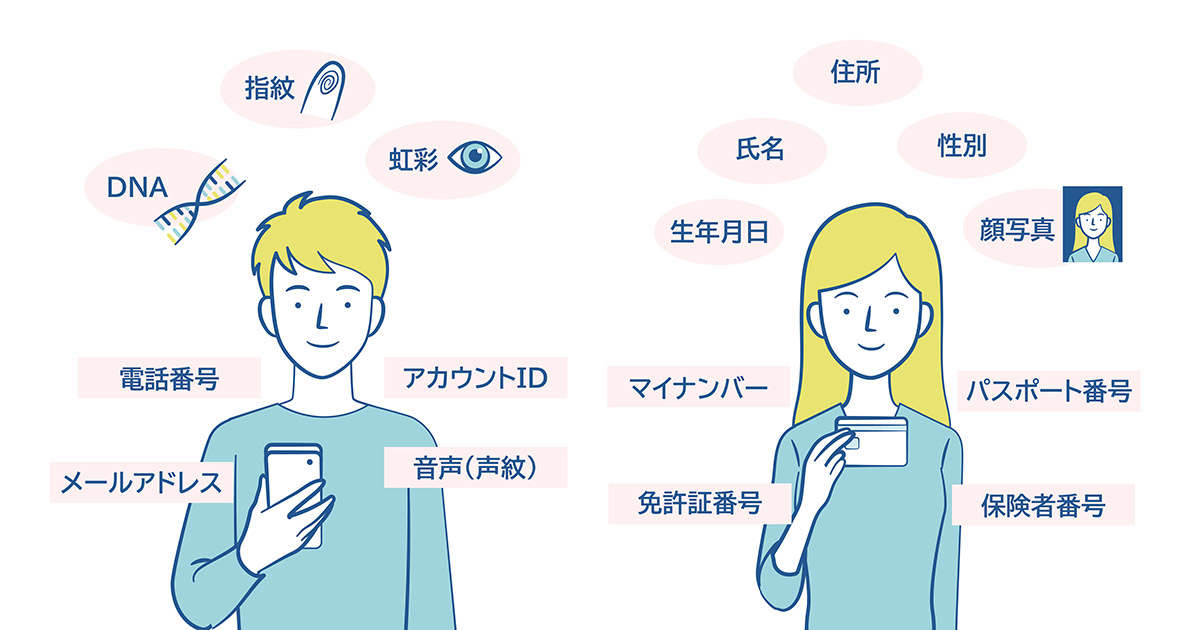
www.sap.com個人情報を含む社内データを学習に使うときの判断基準
基本概念
社内データをAI学習に回すとき、法務・情シス・事業部でまず揃えておきたいのは、「何のデータを、どの目的で、どこまで加工して使うのか」という判断軸です。
要するに、モデル精度の議論より先に、データの法的位置づけを言葉として合わせておかないと、同じファイルを見ていても部署ごとに結論が割れます。
個人情報保護法の整理では、個人情報は生存する個人に関する情報で、氏名やメールアドレスのように単体で個人を識別できるものだけでなく、他の情報と照合して個人を識別できるものも含みます。
営業履歴、問い合わせ文面、商談メモのような業務データも、顧客名や担当者名、会社名、電話番号、所属部署、自由記述欄が組み合わさると個人情報になります。
取得・利用・提供の各場面でそれぞれルールがあります。
その中でも個人データは、個人情報のうち、検索できるように体系化されているものを指します。
実務では、CRMやSFA、MA、問い合わせ管理、メール配信基盤に載っている顧客データの多くがここに入ります。
学習用にCSVへ出力した時点で新しく個人データになるというより、もともと個人データとして管理されていた情報を別用途へ展開する、という理解のほうが現場感に合います。
さらに慎重に扱うべきなのが要配慮個人情報です。
人種、信条、社会的身分、病歴、犯罪の経歴、犯罪被害情報など、本人に対する不当な差別や偏見につながり得る情報が該当します。
営業やサポートのテキストデータでは、表向きは通常の業務文面でも、自由記述欄や返信本文に健康状態、家族事情、休職理由、相談内容が混ざることがあります。
以前、営業メール本文を学習候補にした棚卸しで、名刺情報や署名欄だけを見ていれば問題がなさそうに見えた案件でも、スレッド本文まで追うと要配慮情報が入り込む余地があると早い段階で分かりました。
そのときは抽出後に個別に除去する発想では間に合わず、まず本文全体をどこまで使うのか、自由記述を学習対象から外すのか、先に加工方針を固めてから評価に進めたほうが手戻りが少ないと実感しました。
利用可否の判断では、利用目的の整理が起点になります。
取得時に本人へ示した目的の範囲で使うのか、それともAI学習という新しい利用目的が加わるのかで扱いが変わります。
営業活動のために取得した連絡先を、そのまま生成AIや分類モデルの学習へ回すのは、目的の連続性を丁寧に見ないと説明が立ちません。
実務では「業務改善だから同じ目的」と広く解釈したくなりますが、社外提供や新たな分析用途が絡むと、そこは法務の確認が必要になる場面です。
取得時の通知・公表も軽視できません。
本人から直接取得したデータか、委託元やグループ会社から受け取ったデータかで、必要な整理が変わります。
とくに学習データ基盤へ集約する段階では、元システムごとの取得経路と利用目的の差が表面化します。
情シスは保管場所とアクセス権だけを見がちで、事業部は業務上の有用性だけを見がちですが、法務視点では「その目的で使える状態か」が先です。
第三者提供も判断を誤りやすい論点です。
社内の閉じた環境で学習するのか、外部クラウドや委託先へデータを渡すのかで、必要な整理は一段変わります。
たとえば、社内の分析基盤で仮名加工して使うのと、外部ベンダーのアノテーション環境や生成AIサービスへ投入するのでは、契約・提供先管理・ログの残し方まで含めて別の論点になります。
AIベンダーのAPIに入力する行為も、契約条件や再利用の有無によっては「社内利用だから安全」とは言えません。
実務で判断を揃えるなら、対象データごとに少なくとも次の4点を並べて見ます。
ひとつはそのデータが個人情報かどうか、次に要配慮情報が混ざる余地があるか、さらに利用目的の範囲内か、そして外部へ出るのか社内で閉じるのかです。
この4点が曖昧なままPoCを始めると、途中で法務差し戻しが入り、前処理や評価の工数がそのまま無駄になります。
匿名加工情報と仮名加工情報の違い
匿名加工情報と仮名加工情報は、どちらも「そのままの個人情報を使わない」ための手段ですが、狙いが違います。名前を消しただけでは、どちらにも十分には届きません。
違いを実務で見分けるには、再識別の前提を確認すると整理できます。
匿名加工情報は、元の個人情報から特定の個人を識別できず、元に戻せない状態を目指します。
一方の仮名加工情報は、対応表や識別子の管理を前提に、一定の統制下では元データと結び直せる余地を残します。
営業・マーケティング領域では、行動履歴や属性のつながりを保ったまま学習したいケースが多いため、匿名加工だけで要件を満たせないことがあり、そこで仮名加工が候補に上がります。
| 観点 | 匿名加工情報 | 仮名加工情報 |
|---|---|---|
| 基本的な考え方 | 個人を識別できない状態まで加工する | 直接識別子を外し、対応表を別管理して利用する |
| 再識別リスク | 低く抑えることが前提 | 管理次第で再識別可能性が残る |
| 主な利用場面 | 統計分析、外部共有を含む二次利用の検討 | 社内の分析、モデル開発、効果検証 |
| データの粒度 | 集約やカテゴリ化で情報量が減りやすい | 行動履歴や系列性を比較的保ちやすい |
| 第三者提供との相性 | 条件を満たせば第三者提供の選択肢を取りやすい | 社内限定の利用設計が中心になる |
| 管理の要点 | 加工方法と再識別防止措置の記録 | 対応表の分離保管、アクセス制御、操作ログ |
| 監査で見る点 | 加工ルールの妥当性、再識別防止の説明 | 誰が復元可能か、利用目的とアクセス履歴の一致 |
匿名加工情報で難しいのは、単純なマスキングでは足りない場面が多いことです。
年齢、性別、地域、購買履歴のような準識別子が組み合わさると、氏名がなくても個人が絞り込まれます。
たとえば市区町村単位の居住地、細かな年齢、特定カテゴリの購買履歴をそのまま残すと、社内では「匿名化したつもり」でも、実際には個人に近い輪郭が残ります。
そのため、年代化、地域の集約、カテゴリ変換、頻度情報への置換など、複数の加工を重ねて再識別リスクを落とす発想が必要です。
仮名加工情報は、そこまで情報量を落とさずに済む一方で、管理が甘いと実質的に生データ運用へ戻る点が厄介です。
顧客IDを別番号へ置き換えても、対応表を同じ領域に置き、同じ担当者が両方に触れられる状態なら、加工の意味が薄れます。
現場で機能する形にするには、データ利用者は仮名加工データだけにアクセスし、復元用のマッピングは別管理にする役割分離が必要です。
アクセス申請、承認、操作ログ、定期レビューまで回って初めて、利便性と統制の両立が見えてきます。
学習用途での選び分けは、目的適合性で考えるとぶれません。
個票レベルの時系列や顧客行動の連続性が必要なら、仮名加工情報のほうが現実的です。
逆に、セグメント傾向の把握や傾向分析が中心で、個人単位の連続性が不要なら、匿名加工情報へ寄せたほうが安全側です。
どちらも難しい、あるいは加工後に目的を満たせないなら、そのデータは学習対象から外す判断も必要になります。
この選択を実務で迷わないようにするには、簡易な判断フローを持っておくと運用が安定します。
まず、生データでなければ目的を達成できないかを問い、代替可能なら生データ利用は避けます。
次に、個人単位の連続性が必要なら仮名加工を候補にし、不要なら匿名加工を優先します。
そのうえで、要配慮個人情報が混ざる、利用目的との距離が遠い、外部提供が避けられない、再識別リスクが下げ切れない、といった条件が重なるなら除外に寄せます。
ここでのポイントは「使えるように加工する」ではなく、「目的を満たしながら、どこまで情報量を落とせるか」です。
ℹ️ Note
匿名加工と仮名加工のどちらを選ぶ場合でも、監査で効くのは加工後データそのものより、なぜその方式を選んだかの記録です。目的、残す項目、落とす項目、再識別リスクの見立て、承認者が残っていれば、後続の再学習や削除対応でも判断がぶれません。
生成AI入力時の注意と社内ルール
生成AIを使う場面では、学習データ整備よりも入力の敷居が低いため、現場でルール逸脱が起きやすくなります。
チャット欄に貼り付けるだけで要約や分類が試せる反面、その手軽さが一番のリスクです。
社内では「モデル学習用データ」と「生成AIへの都度入力」を別物として扱いがちですが、どちらも個人情報や機密情報が外部サービスへ渡る可能性がある点では同じ土俵にあります。
そのため、社内ルールの起点は明快である必要があります。
基本線は、PIIを含む生データと機密情報は生成AIへ入力しないです。
氏名、メールアドレス、電話番号、住所、社員番号、商談固有情報、契約条件、未公開の製品情報、自由記述の相談内容は、要約したくなる典型ですが、そのまま入れてはいけない対象です。
営業メールや問い合わせ履歴はとくに危険で、署名欄や文中の固有名詞を外しても、案件名、日付、商品構成、経緯説明の組み合わせで個人や法人が特定できることがあります。
Google Cloudの『データガバナンス解説』が示すように、データ活用ではポリシーと責任分担を一体で設計する必要があります。
生成AI運用でも同じで、禁止事項だけでは回りません。
誰が入力可否を判断し、どのサービスが承認済みで、ログをどこに残し、違反時にどう止めるのかまで決めておかないと、ルールは紙のままになります。
実務上は、生成AI入力に関する社内ルールを少なくとも3層に分けると整理しやすくなります。
1つ目は入力禁止データの定義です。
個人情報、要配慮個人情報、契約・価格情報、認証情報、ソースコード、未公開資料などを明示し、自由記述欄や添付ファイルも対象に含めます。
2つ目は承認済み利用環境の限定で、ブラウザ版の公開サービス、契約済みの法人向け環境、社内閉域の推論基盤を区別します。
3つ目は記録と統制で、プロンプトログ、利用目的、出力の保存先、持ち出し可否、アクセス権を運用に落とします。
ログ保管の扱いも論点です。
生成AIサービス側に入力ログが残るのか、社内でも利用記録を残すのかで、監査の前提が変わります。
法人契約の有無だけで安心するのではなく、入力データがモデル改善に使われるか、管理者が監査ログを取得できるか、出力をどこへ保存できるか、といった運用条件まで見ないと統制になりません。
情シスはSSOやアクセス制御、事業部は利用目的、法務は同意や第三者提供の整理を見ることになり、ここでも横断判断が必要です。
同意の考え方も混同されやすいところです。
社内データだから同意は不要、という単純な整理にはなりません。
取得時に示した利用目的の範囲、外部サービスへの送信有無、委託か第三者提供かといった論点が絡むためです。
とくに、顧客とのやり取りを生成AIへ投入して文面生成や要約に使うケースは、社内効率化の名目だけで進めると危うくなります。
持ち出し制御も欠かせません。
承認済み環境以外へのコピー、個人アカウント利用、ファイルアップロード、ブラウザ拡張経由の送信など、運用の抜け道は複数あります。
ここは利用者教育だけでなく、DLP、CASB、端末制御、監査ログの突合といった仕組み側の制御も必要です。
テクノロジーの観点から見ると、ルール違反を「注意喚起」で防ぐより、送れない設計にしたほうが事故は減ります。
個別案件では、データを見た瞬間に判断が難しいケースが必ず出ます。
たとえば、顧客名を落とした営業メール本文、従業員番号を置換した人事データ、問い合わせ要約済みのサポートログは、一見すると入力できそうに見えます。
ただ、本文中の文脈や時系列、属性の組み合わせで再識別の余地が残ることがあります。
こうした案件は現場判断で押し切らず、法務確認を前提にしたほうが全体最適です。
生成AIは入力が一瞬でも、後から説明責任を負うのは組織全体だからです。
品質管理で最低限見るべき指標
データ品質KPI一覧
データ品質は「集まっているか」ではなく、「学習や評価に通してよい状態か」で見る必要があります。
要するに、件数が多いだけでは足りず、欠け方、間違い方、混ざり方まで管理項目に落とさないと、後工程で手戻りが増えます。
IBMの『トレーニング・データ解説』でも、トレーニングデータはモデル性能の土台として扱われていますが、実務ではその土台をどう測るかが抜けやすいところです。
最低限そろえたいのは、完全性、正確性、一貫性、最新性、重複率、欠損率、重複排除後の有効件数です。
完全性は必要な項目が埋まっているかを見る指標で、営業ログなら顧客ID、日付、接点種別、結果ステータスがそろっているかが典型です。
正確性は値そのものが事実に合っているかで、商談ステージの更新漏れや、商品コードの誤登録がここに当たります。
一貫性は同じ意味のデータが別テーブルや別システムで矛盾していないかを見る観点で、SFAとMAで企業名や担当者属性の定義がずれていると、集計以前に学習特徴量が崩れます。
最新性も外せません。
営業領域では、古い失注理由や過去の価格条件が混ざるだけで、現行の商材構成と合わない学習データが増えます。
たとえばキャンペーン条件が変わったあとも旧条件の案件が主成分として残ると、モデルは過去の営業現場を学習してしまいます。
最新性は「何日以内が有効か」という単純な日数だけでなく、制度改定、商品改定、組織変更の境目で区切って管理したほうが運用上の意味が出ます。
営業データでとくに効くのが重複率です。
リード統合前のCRMでは、同一企業が別名義で入り、担当者違いで複数登録され、メール履歴まで重なっていることが珍しくありません。
この状態で学習用と評価用を分けると、見かけ上は別レコードでも実質的には同じ案件が両方に入ります。
現場感としても、営業領域では重複率と評価データの独立性を最優先に置くだけで、PoCの再現性が目に見えて安定します。
スコアが良かったのに本番で伸びない案件は、後から見るとこの2点で崩れていることが多いです。
欠損率は列ごとだけでなく、クラスやユースケース別でも見ておく必要があります。
たとえば受注案件だけ詳細メモが豊富で、失注案件は自由記述が空欄だらけなら、モデルは営業活動の実態ではなく「入力が丁寧な案件」を学習しがちです。
重複排除後の有効件数も同時に見ないと、元の件数だけでは学習可能なボリュームを見誤ります。
1万件あるように見えても、重複除去と必須項目フィルタ後に残るのが数千件なら、サンプリング戦略も評価設計も変わります。
モデル運用を見据えるなら、収集段階のKPIだけでは足りません。
クラスやユースケースのカバレッジ、データ分布の安定性、バイアス指標、評価データの独立性まで同じ管理表で追う必要があります。
カバレッジは「主要な問い合わせ種別を一通り含むか」「主要商材ごとに十分な件数があるか」といった網羅性です。
データ分布は、月ごと・部門ごと・チャネルごとの偏りが急に変わっていないかを見るもので、分布の変化を見落とすと、学習時には高精度でも運用開始後に外れます。
バイアスは特定顧客層、地域、担当者、チャネルに予測が偏っていないかを確認する軸で、営業評価や優先順位付けに使うモデルではとくに無視できません。
評価データの独立性は、前述の通り、テストの信頼性そのものを支える条件です。

トレーニング・データとは| IBM
トレーニング・データは、予測を行う方法、パターンを認識する方法、またはコンテンツを生成する方法を機械学習モデルに教えるために使用される情報です。
www.ibm.comアノテーション品質KPI
アノテーション工程では、件数の進捗より品質の安定度を先に見たほうが、後から効きます。
ラベルが付いていることと、学習に使えることは別だからです。
前の工程でデータ自体を整えていても、ラベル付けの基準がぶれると、モデルはノイズを学習します。
ここでの基本KPIは、ガイドライン遵守率、ラベル一致率、再現性、ダブルチェック率、監査指摘率です。
ガイドライン遵守率は、定義済みの判断基準に沿ってラベルが付けられている割合を見ます。
たとえば「問い合わせ分類」で、価格質問と導入相談の境界条件が文書化されていても、注釈者ごとに解釈が異なるなら、ガイドラインは存在していても機能していません。
監査で見るべきなのは、文書の有無ではなく、実際の判断がその文書に戻せるかです。
ラベル一致率、つまりInter-Annotator Agreementは、複数の注釈者が同じデータに同じ判断を下せるかを見る中心指標です。
ここが低いときは、注釈者の技量不足より先に、ラベル定義が曖昧なケースを疑ったほうがよい場面が多いです。
営業メールや問い合わせログでは、複数意図を含む文面が普通に出てきます。
そのとき単一ラベルを強制するのか、主ラベルと副ラベルを分けるのかで、一致率は大きく変わります。
数値だけを追うのではなく、「どのクラスで割れるのか」を見ると、ガイドラインの改訂点が見えてきます。
再現性は、時間を空けても同じ基準で同じラベルが付くかという観点です。
初回アノテーションでは揃っていても、数週間後に同じサンプルを再注釈すると結果がずれることがあります。
これは担当者の記憶に基づく一時的な整合で、ルールが定着していない状態です。
再現性を見ておくと、短期のPoC向けラベリングなのか、継続運用できる教師データなのかを切り分けられます。
ダブルチェック率は、どれだけのデータが二重確認を通っているかを見る指標です。
全件を二重化する必要はありませんが、曖昧クラス、新規ラベル、境界事例に重点を置いて二重確認をかけると、品質コストのかけ方に無駄が出ません。
監査指摘率は、サンプル監査や品質レビューでどれだけ修正が発生したかを見る値で、外部委託でも内製でも有効です。
委託先の作業品質を見るだけでなく、発注側の指示書が足りているかを映す鏡にもなります。
アノテーション品質はモデル評価とも直結します。
クラスのカバレッジが偏っていると、一致率が高く見えても意味がありません。
たとえば多数派クラスばかりにラベルが集中していると、稀少だが業務上は重要なクラスをモデルが拾えなくなります。
バイアスも同じで、特定業界や特定顧客規模の問い合わせだけでラベル設計を固めると、他の顧客層に広げたときに分類軸が崩れます。
アノテーション品質KPIは、注釈者の精度管理だけでなく、学習対象の世界をどこまで再現できているかを見るための指標でもあります。
ℹ️ Note
ラベル一致率が落ちたとき、注釈者の教育不足と決めつけると修正が遅れます。実務では、割れたサンプルを見に行くと、ラベル定義そのものが業務実態に追いついていないことが少なくありません。判断が割れた記録をガイドラインへ戻す運用のほうが、追加教育だけを繰り返すより効きます。
品質管理テンプレート
品質管理は、収集、アノテーション、評価の三層で切り分けると回しやすくなります。
1枚の管理表に全部を詰め込むより、工程ごとに「何を満たせば次へ進めるか」を定義したほうが、責任範囲も明確になります。
Google Cloudの『データガバナンス解説』が整理するように、データ活用ではポリシーだけでなく、誰が何を管理するかまで含めて設計する必要があります。
品質KPIも同じで、値だけ並べても、判定者と是正フローがなければ運用になりません。
テンプレートの考え方としては、収集層ではデータそのものの健全性、アノテーション層ではラベルの信頼性、評価層ではモデル検証に使うデータの妥当性を追います。
目標値は業務とリスクで変わるため固定値ではなく、まずは目標例として置き、運用しながら見直す前提が現実的です。
営業・マーケ領域なら、収集層で完全性、欠損率、重複率、重複排除後の有効件数、最新性を持ち、アノテーション層でガイドライン遵守率、ラベル一致率、再現性、ダブルチェック率、監査指摘率を管理し、評価層でカバレッジ、データ分布、バイアス、評価データの独立性を確認する構成が扱いやすいのが利点です。
以下のような形で整理すると、会議でも監査でも使い回しが利きます。
| 層 | KPI項目 | 何を見るか | 目標例 | 判定時の論点 |
|---|---|---|---|---|
| 収集 | 完全性 | 必須項目が埋まっているか | 学習必須列が定義済みで未充足案件を把握 | 欠損が特定部門や期間に偏っていないか |
| 収集 | 正確性 | 値が元業務と整合しているか | サンプル監査で誤登録パターンを継続把握 | 誤りが入力運用由来か連携由来か |
| 収集 | 一貫性 | システム間で定義がぶれていないか | 主要マスタの定義差分を棚卸し済み | SFA、CRM、MAで同義項目が衝突していないか |
| 収集 | 最新性 | 現行業務を表すデータか | 制度改定や商品改定の境界で分割管理 | 古い案件が学習多数派になっていないか |
| 収集 | 重複率 | 同一案件や同一顧客の重なり | 重複検知ルールを固定し推移監視 | 名寄せ前提の重複を放置していないか |
| 収集 | 欠損率 | 列別・クラス別の欠け方 | 重要列の欠損を継続監視 | 特定ラベルだけ記録密度が薄くないか |
| 収集 | 重複排除後の有効件数 | 実際に使える件数 | 学習対象ごとの最終件数を確定 | 元件数ではなく残存件数で判断しているか |
| アノテーション | ガイドライン遵守率 | 定義通りに付与されているか | 監査サンプルで逸脱傾向を把握 | ルール未読ではなく定義曖昧が原因ではないか |
| アノテーション | ラベル一致率 | 注釈者間の一致度 | 割れやすいクラスを特定して改訂 | 一致率の低さが境界設計由来ではないか |
| アノテーション | 再現性 | 時間を置いても同じ判断になるか | 再注釈サンプルで確認 | 記憶ではなく文書で再現できるか |
| アノテーション | ダブルチェック率 | 二重確認の適用範囲 | 曖昧ケースに重点適用 | 全件主義で工数が膨らんでいないか |
| アノテーション | 監査指摘率 | 品質レビューでの修正発生率 | 指摘内容を類型化して継続追跡 | 作業者より指示書の問題ではないか |
| 評価 | カバレッジ | クラスやユースケースの網羅 | 主要ケースを評価対象に含める | 本番で使うケースが抜けていないか |
| 評価 | データ分布 | 学習時と評価時の偏り | 期間・部門・チャネル別に確認 | 偏った評価セットで高スコア化していないか |
| 評価 | バイアス | 特定属性への偏り | 主要属性別の差分を把握 | 顧客層や担当者で不利な判定が出ていないか |
| 評価 | 評価データの独立性 | 学習データと混ざっていないか | 分割ルールを固定し監査可能にする | 同一案件系列や重複レコードが混入していないか |
この三層管理にしておくと、問題が出たときに「モデルが悪い」の一言で片付かなくなります。
評価精度が落ちたときも、収集側の最新性が崩れたのか、アノテーションの一致率が下がったのか、評価データの独立性が壊れたのかを切り分けられます。
営業DXの現場では、モデルのチューニングより前にこの管理表を埋めるだけで、どこで再現性を失っているかが見えるようになります。
感覚で「データが荒れている」と言う段階から、管理項目として説明できる状態へ移すことが、このセクションで押さえたい判断材料になります。
社内ガバナンス設計のテンプレート
役割と責任
社内ガバナンスを運用に落とすときは、規程の文章量よりも、誰がどの場面で判断を持つかを先に固定したほうが止まりません。
要するに、データ利用の可否、加工方法の妥当性、本番投入の承認が、会議体の空気で決まる状態を避けることが出発点です。
Google Cloudの『データガバナンス解説』でも、ポリシーと役割定義をセットで扱う考え方が整理されていますが、AIトレーニングデータではこの前提が特に効きます。
データ準備に工数が偏る領域では、責任のあいまいさがそのまま再作業になります。
実務では、RACI風に「実務を回す人」「最終的に責任を持つ人」「事前に相談を受ける人」「結果を共有される人」を整理すると、承認の往復が減ります。
データオーナーは、そのデータを業務上管理する責任者として、利用目的の妥当性と事業上の必要性に責任を持ちます。
たとえば営業データなら営業企画や事業部長クラスが該当し、元データをAI学習に使う意味があるか、業務定義と矛盾していないかを判断します。
最終決裁者をこの役割に置くと、現場が「使ってよいのか」を延々と持ち回りする状態を避けられます。
データスチュワードは、データオーナーの下で定義、品質、加工履歴、アクセス権を日常的に管理する役割です。
列定義のズレ、重複、欠損、匿名加工や仮名加工の適用ルール、評価用データの分離といった実務はこの役割が中心になります。
モデル開発側に近い担当者が兼務することもありますが、学習精度だけを見て走ると権利確認や加工記録が抜けるため、データ管理の観点を独立させておくほうが事故を防げます。
法務は、利用目的、同意の範囲、契約上の利用許諾、第三者提供該当性、匿名加工情報や仮名加工情報の扱いを確認する役割です。
個人情報の扱いは「社内利用だから自由」という話にはなりません。
法務が見るべきなのは、条文の読解だけではなく、データの来歴と利用シナリオが整合しているかです。
契約で二次利用が制限されているデータを学習に投入していないか、匿名加工のつもりでも再識別余地が残っていないか、といった論点がここに入ります。
情報セキュリティは、アクセス制御、保管場所、鍵管理、持ち出し制限、操作ログ、委託先管理を担います。
仮名加工情報を使うなら、対応表の分離保管と閲覧権限の切り分けはこの部門が設計の中心です。
モデル開発環境と業務本番環境を分ける、外部アノテーション先への受け渡し経路を限定する、再学習時に古いデータを勝手に再投入できないようにする、といった制御もここで決まります。
AI責任者は、モデル単体ではなく、データ利用から評価、本番運用、再学習までを横断して整合を取る役割です。
事業部、法務、セキュリティ、開発が別々に正しいことを言っていても、全体として進まないケースは珍しくありません。
この役割があると、「PoCでは許容したが本番では追加統制が必要」「精度が出ても説明責任を満たしていないので差し戻す」といった判断を一本化できます。
AI推進室やデジタル部門の責任者が担う形が多いですが、肩書きよりも、部門横断で優先順位を決められる立場であることが効きます。
監査部門は、申請通りに運用されているか、記録が残っているか、例外処理が野放しになっていないかを後追いで検証する役割です。
監査は本番後だけに入るものと思われがちですが、PoC段階から記録様式だけでもそろえておくと、拡張時の手戻りが減ります。
監査部門が見るのはモデル精度そのものより、意思決定と証跡の一貫性です。
誰が承認し、どのデータを、どのルールで加工し、どの版のモデルに使ったかがたどれない状態では、品質問題もコンプライアンス問題も切り分けられません。
複数事業部にデータが分散している組織では、中央集権型で全部を本部承認に寄せると詰まり、逆に各部門へ任せ切ると定義がばらつきます。
DX推進の現場で摩擦が少なかったのは、中央で最小標準だけを決め、現場がその枠内で実装するハイブリッド型でした。
たとえば本部側で申請書式、必須記録項目、権限設計、再評価周期の考え方を統一し、営業部門やカスタマーサクセス部門は自部門データのラベル定義や業務ルールを持つ形です。
この分け方だと、標準化と現場適用の両方が残ります。
承認フローと記録テンプレート
フローは複雑に見えても、実際には「申請」「法務・セキュリティ審査」「学習実施」「品質監査」「本番承認」「定期再評価」の6段階に分けると運用が安定します。
ここで大事なのは、承認者を増やすことではなく、各段階で次に進める条件を固定することです。
止まる案件の多くは、誰かが反対しているのではなく、必要な記録が不足していて判断できない状態です。
- データ利用申請
起点は、利用部門またはAI開発チームによる申請です。
申請書には、利用目的、対象データセット、データオーナー、利用範囲、予定する加工方法、学習対象モデル、想定出力、評価方法を入れます。
この時点で、実データを使うのか、匿名加工データや仮名加工データに置き換えるのか、合成データを併用するのかまで書いておくと、後段の差戻しが減ります。
- 法務・情報セキュリティ承認
法務は、権利関係、同意範囲、契約制限、個人情報該当性、加工区分を確認します。
情報セキュリティは、保管先、アクセス権、ログ取得、委託有無、対応表の管理方法を確認します。
ここでは「可否」だけでなく、「仮名加工に変更」「閲覧権限を限定」「持ち出し禁止環境でのみ作業」といった条件付き承認を扱えるようにしておくと、業務を止めずに統制を入れられます。
- 学習実施
承認済みデータだけを学習環境へ投入し、利用したデータ版、加工版、特徴量生成ルール、除外条件、実行者、実行日を残します。
PoCではここが雑になりがちですが、本番に近づくほど「どの学習結果がどのデータに由来するか」を追えることが効いてきます。
特に再学習では、前回との差分が記録されていないと、精度変動の原因が追えません。
- 品質監査
ここではモデルのスコアだけではなく、評価データの独立性、ラベル定義の一貫性、対象業務との整合、バイアス確認、サンプルレビュー結果を見ます。
監査部門が全部を見る必要はなく、データスチュワードとAI責任者が一次レビューし、監査部門は証跡と運用逸脱の有無を確認する形が現実的です。
- 本番承認
本番投入の決裁は、データオーナーとAI責任者を中心に行い、法務と情報セキュリティは必要に応じて再確認します。
PoCで許可された用途を超えていないか、運用監視項目が定義されているか、障害時の停止条件があるかをここで見ます。
精度が出ているだけでは承認せず、説明可能な運用単位に整理されているかまで見ておくと、導入後の混乱が減ります。
- 定期再評価
本番化したモデルは、放置せず定期的に再評価します。
再評価では、データ分布の変化、ラベル定義の改訂、苦情やインシデント、アクセス権の見直し、再学習の必要性を点検します。
申請時に想定していた利用目的から外れていないかを確認する工程でもあります。
このフローを回すための記録テンプレートは、1枚に全部盛り込むより、台帳を分けたほうが管理しやすくなります。
最低限必要なのは、データセット台帳、加工記録台帳、権利・同意確認台帳、評価結果台帳、モデル版管理台帳、再学習ログです。
具体的には次の項目を押さえると、監査でも開発でも共通言語になります。
| 記録台帳 | 必須項目 | 主な管理主体 | 保持期間の目安 |
|---|---|---|---|
| データプロベナンス台帳 | 元システム、取得日時、取得条件、対象範囲、データオーナー、利用目的 | データスチュワード | 少なくとも当該モデルの運用期間中と終了後の監査対応期間 |
| 加工内容台帳 | 匿名加工・仮名加工の方法、除外列、集約ルール、変換ロジック、実施者、実施日 | データスチュワード | 元データとの対応関係を説明できる期間 |
| 同意・権利台帳 | 同意取得の有無、利用許諾、契約上の制約、第三者提供該当性、法務確認日 | 法務 | 契約・利用関係を説明できる期間 |
| 評価結果台帳 | 評価データ版、評価観点、レビュー結果、指摘事項、是正内容、承認者 | AI責任者 | モデル版の利用履歴を追える期間 |
| モデル版管理台帳 | モデルID、学習データ版、特徴量版、学習日時、実行者、本番反映日、停止日 | AI責任者 | 本番利用終了後も遡及確認できる期間 |
| 再学習ログ | 再学習理由、変更差分、使用データ、評価差分、承認履歴、反映結果 | AI責任者 | 少なくとも後続版との比較が可能な期間 |
保持期間は法令、契約、業界規制で変わるため固定の年数を機械的に置くより、当該モデルの運用期間中に加えて、停止後も監査と問い合わせ対応が可能な期間という考え方で定義しておくと、用途ごとの差を吸収できます。
数値を先に置くと、モデルだけ止めて記録を消す運用になりがちですが、実際に問われるのは「なぜその判断をしたか」を後から説明できるかです。
💡 Tip
PoCから本番へ広げるなら、本部が標準テンプレートを持ち、現場が業務項目を追記する運用が収まりやすいのが利点です。たとえば本部は申請書、権利確認欄、加工記録欄、版管理欄を共通化し、営業部門は商談ステータス定義、サポート部門は問い合わせ分類定義だけを追加します。この構成だと、部門ごとに言葉は違っても、監査で見る枠組みはそろいます。
監査・再評価・廃棄ルール
監査と再評価は、導入後のチェックイベントではなく、データ利用のライフサイクルそのものです。
学習前に承認されたデータでも、業務の変更や制度改定で前提が崩れることがあります。
AIの運用では、モデルの性能低下より先に、データの意味が変わっていることが少なくありません。
営業プロセスの入力ルール変更、商材区分の改訂、問い合わせカテゴリの再編などが入ると、過去のラベルや特徴量はそのままでは使えなくなります。
監査部門が見るべきポイントは、申請書と実運用の一致、アクセス権の逸脱、加工ルールの未記録、再学習時の無承認変更、停止済みモデルのデータ残置です。
ここで効くのは、紙の規程よりログです。
仮名加工情報の対応表に誰がアクセスしたか、どのデータ版で学習したか、評価結果に差し戻しがあったかが残っていれば、問題発生時の切り分けが進みます。
逆に、担当者の記憶に依存すると、モデル品質の議論とコンプライアンスの議論が混線します。
再評価は、定期点検とイベント起点の両方を持つと回ります。
定期点検では、対象データの定義変更、データ分布の変化、アクセス権レビュー、苦情・問い合わせの有無、監査指摘の再発を確認します。
イベント起点では、法改正、事業再編、外部委託先変更、重大インシデント、性能劣化、再識別リスクの見直しがトリガーになります。
経済産業省のAI原則実践のためのガバナンス・ガイドラインが示すように、AIガバナンスは導入時の審査だけで閉じず、運用中のリスク把握と改善まで含めて設計するものです。
廃棄ルールも最初から決めておく必要があります。
廃棄対象は、元データ、加工済みデータ、特徴量データ、評価データ、モデル本体、再学習用中間生成物、対応表で分けて扱います。
特に仮名加工情報の対応表は、廃棄判断が曖昧だと、利用終了後も復元可能性だけが残ります。
利用目的が終了したデータ、承認範囲を外れたデータ、更新停止で再利用価値がないデータは、削除責任者、削除方法、削除記録を定義して閉じる形が必要です。
モデルだけ停止して、学習用コピーや一時出力が残る運用は避けたいところです。
実務では、廃棄を「完全削除」だけで考えず、利用停止、アーカイブ、証跡保持、対応表削除を分けると整理しやすくなります。
たとえば監査対応のために評価結果台帳と承認履歴は残す一方、再識別につながる対応表は先に削除する、といった設計です。
これなら説明責任とリスク低減を両立できます。
複数事業部の分散データを扱う組織では、この監査・再評価・廃棄の設計でもハイブリッド型が機能します。
本部は「どの記録を残すか」「どのイベントで再評価するか」「どの状態を廃棄完了とみなすか」を最小標準として定義し、各事業部は自部門データの意味変更や運用停止条件を追加します。
中央で全データを細かく管理しようとすると現場知識が足りず、各部門に任せ切ると証跡がバラバラになります。
最小標準を中央で押さえ、現場が業務文脈を埋める形にすると、監査で必要な粒度と現場運用の速度が両立します。
これはPoC段階でも本番段階でも効く設計で、部門横断のAI活用を広げるときほど差が出ます。
比較と選び分け:データ種別・アノテ体制・ガバナンス型
データ種別の比較表
営業DXの現場で迷いやすいのは、「どのデータを使うと精度が出るか」と「どのデータなら運用が止まらないか」が一致しない点です。
要するに、現場再現性だけでSalesforceやHubSpotの商談履歴、ZendeskやServiceNowの問い合わせログをそのまま学習に入れると、モデルは業務文脈をよく拾います。
権利確認、加工記録、アクセス制御、監査証跡まで含めた運用コストが一気に立ち上がります。
IBMの『トレーニング・データとは』が整理する通り、学習データはモデル性能の土台ですが、実務では「使えるデータ」と「使って回せるデータ」を分けて考える視点が欠かせません。
| 観点 | 実データ | 匿名加工・仮名加工データ | 合成データ |
|---|---|---|---|
| 現場再現性 | 高い | 中程度 | 条件次第 |
| 個人情報リスク | 高い | 低減可能 | 低いがゼロではない |
| 法務確認の難易度 | 高い | 高い | 中程度 |
| データ不足への対応 | 弱い | 中程度 | 強い |
| バイアス伝播リスク | 元データ依存 | 元データ依存 | 生成元次第で増幅もあり |
| 説明責任 | 元データ台帳が必要 | 加工ルール記録が必要 | 生成プロセスの記録が必要 |
実データの強みは、現場のクセまで含めて学習できることです。
たとえば問い合わせ要約では、顧客の言い回し、担当者の記録癖、製品名の略称、社内独自のカテゴリ運用まで入ってくるため、机上で作ったサンプルよりも実運用に近い精度が出ます。
ただし、説明責任の難所も同じ場所にあります。
どの期間のログを取り込み、どの属性を除外し、誰の承認で学習対象にしたかが追えないと、精度の議論とコンプライアンス対応が切り離せません。
匿名加工情報や仮名加工情報は、その中間に置きやすい選択肢です。
前述の通り、匿名加工情報は再識別を避けるために情報量が削れますが、仮名加工情報は対応表を分離管理する前提で、時系列や行動履歴を比較的保ちやすい構造です。
営業やサポート領域では、案件進行や問い合わせ履歴の連続性が残るかどうかで、学習に使える価値が変わります。
『個人情報保護委員会』のガイドライン体系でも、匿名加工と仮名加工は同じ「個人情報リスク低減」ではなく、利用目的と管理方法が異なるものとして扱うのが筋です。
実務上は、問い合わせ要約のように文脈保持が効くタスクでは、実データを起点にしつつ、直接識別子を仮名加工で切り離し、最終判断を人が返す構成が収まりやすい場面が多くあります。
現場でも、実データだけで始めると法務とセキュリティの調整に時間がかかり、匿名加工に寄せすぎると要約の粒度が落ちるため、仮名加工を挟んで人がレビューする流れのほうが、品質と立ち上がり速度の釣り合いが取りやすいと感じます。
これは一般化して言えば、「文章タスクでは文脈を落としすぎない加工」と「最終出力を人が閉じる運用」を組み合わせると失敗が少ない、ということです。
合成データは、件数不足や偏り補正に効くカードです。
たとえば新商材の失注理由や、まだ発生件数が少ない問い合わせカテゴリは、実データだけでは学習量が足りません。
そこを補う目的で合成データを使う価値はあります。
ただし、生成元の分布やルールが偏っていると、その偏りを薄めるどころか強めることがあります。
国連大学の『合成データ利用に関する提言』でも、プライバシー低減だけでなく、生成過程の記録とバイアス検証がセットで求められています。
営業DXで使うなら、合成データを主食にするより、実データや仮名加工データで足りないクラスを補う副材料として扱うほうが安定します。
再識別、バイアス、説明責任の3つで見れば、選び分けの軸は明確です。
再識別リスクを最優先する外部共有や共同研究なら匿名加工や合成データが前に出ます。
業務文脈を落としたくない社内モデル開発なら仮名加工が中核になります。
説明責任まで含めると、どの方式でも「安全だから記録不要」にはなりません。
実データなら元台帳、加工データなら加工ルール、合成データなら生成条件と元分布の記録が必要で、そこを省くと監査時に比較不能になります。
アノテーション体制の比較表
ラベル付けの方式は、精度より先に運用体制で決まることが多いです。
営業部門やカスタマーサクセス部門では、正解ラベルそのものが業務定義に依存するため、単に安く早く付ければよいわけではありません。
たとえば「失注理由」「問い合わせ意図」「要対応度」は、現場で使う定義が揺れていると、ラベルのばらつきがそのままモデルのばらつきになります。
| 観点 | 内製アノテーション | 外部委託アノテーション | HITL併用 |
|---|---|---|---|
| 業務知識の反映 | 高い | 低〜中 | 高い |
| スケール | 低い | 高い | 中〜高 |
| 品質の均一化 | ルール次第 | ベンダー次第 | 比較的高い |
| コスト管理 | 見えにくい | 見えやすい | やや複雑 |
| ガバナンス負荷 | 中 | 高 | 高 |
内製の魅力は、業務知識がそのままラベルに入ることです。
たとえばSalesforce上で営業責任者が「商談停滞」と見なすケースと、インサイドセールスが同じ言葉で指すケースがずれることがあります。
こうしたズレは、業務を知らない人には判定できません。
そのため、初期のラベル設計や基準書づくりは内製が向きます。
ただし、担当者ごとの解釈差を放置すると、同じログでも答えが割れます。
内製は知識を反映できる反面、ルールを文章化しない限り属人化が進みます。
外部委託は、件数を一気に積み上げたいときに効きます。
問い合わせ分類や要約評価のように大量処理が必要なタスクでは、ベンダーの作業ラインを使う意味があります。
ただ、品質の安定は委託先そのものより、発注側がどこまで基準を固定したかで決まります。
秘密保持契約を結んだだけでは足りず、どの画面を見せるか、再委託を許可するか、サンプル監査をどう回すかまで設計しないと、ガバナンス負荷はむしろ増えます。
その中間にあるのがHITL併用です。
AIで一次ラベルや要約案を出し、人が確認・修正する流れにすると、業務知識と処理量の両方を取りにいけます。
問い合わせ要約の学習では、この構成が実務上もっとも収まりが良い場面を多く見ます。
実データを仮名加工したうえで、モデルが下書きを作り、現場担当者が差分だけ直す形にすると、ゼロから全文を書くより速く、外部委託だけに寄せるより文脈のズレも抑えられます。
特に営業DXの現場では、要約文の自然さより「次に誰が何をするか」が抜け落ちないことが大切なので、人の確認を最後に置く意味が大きいです。
ℹ️ Note
スモールスタートの段階では、全件を人手で丁寧に付けるより、AIで候補を出して人が誤りだけ直す設計のほうが、基準書の改善点も見えます。正解ラベルを作る工程そのものが、業務定義の棚卸しになります。
品質、スケール、コスト、ガバナンス負荷をまとめて見ると、選び分けは次のようになります。
業務定義が固まっていない初期段階は内製寄り、定義が固まって件数が膨らんだら外部委託を混ぜる、継続運用ではHITLで人の確認対象を絞る、という流れです。
要するに、方式を固定するより、フェーズで配分を変えるほうが現実的です。
PoCの時点で全面委託に寄せると基準書が弱くなり、本番移行後に差し戻しが増えます。
逆に、ずっと内製のままだと運用が回らず、改善サイクルが遅れます。
ガバナンス型の比較表
ガバナンス構造も、理想論だけでは決まりません。
営業DXでは、中央集権に寄せるほど標準化は進みますが、現場の案件進行や部門固有の定義変更に追随しにくくなります。
分散に寄せるとスピードは出ますが、監査や横断比較で困ります。
Google Cloudの『データガバナンスとは』やSAPの解説が共通して示すのは、ポリシー、役割、手順を定義しても、それをどこに集約するかで運用の性格が変わるという点です。
| 観点 | 中央集権型ガバナンス | 分散型ガバナンス | ハイブリッド型ガバナンス |
|---|---|---|---|
| 標準化 | 高い | 低い | 高い |
| 現場スピード | 低い | 高い | 中程度〜高い |
| 品質のばらつき | 低い | 高い | 中程度 |
| 中堅企業との相性 | やや低い | 中程度 | 高い |
| 監査対応 | しやすい | しにくい | しやすい |
中央集権型は、本部主導で台帳、承認、加工ルール、評価基準をまとめる形です。
金融や規制産業のように、全社標準を崩せない領域では有効です。
ただ、中堅企業の営業現場では、本部が全ユースケースを理解しきれず、申請待ちが積み上がることがあります。
役割が曖昧なまま中央審査に寄せると、誰が最終判断者なのか見えず、承認経路だけが増えます。
RACIを使ってAccountableを明確にしたプロジェクトでは、データ収集や外部提供の可否判断が止まりにくくなりますが、これは構造の問題というより責任線の問題です。
分散型は、事業部や現場チームが判断権を持つため、試行の速度が出ます。
HubSpot運用チームが問い合わせ分類モデルを回し、Salesforce運用チームが案件スコアリングを別管理で進めるような形です。
ただし、項目定義、評価基準、廃棄ルールが部門ごとにズレると、あとで比較不能になります。
監査の場面では、「なぜ同じ顧客データなのに部署ごとに管理方法が違うのか」に答えづらくなります。
そのため、営業DXの現場ではハイブリッド型がもっとも現実に合います。
本部が最小標準を持ち、現場が業務定義を追加する構造です。
たとえば本部は、申請書式、加工区分、記録項目、アクセス権レビュー、評価台帳の形式だけを統一します。
営業企画やカスタマーサクセス部門は、その上に「失注理由の定義」「要約で落としてはいけない項目」「アラート対象の問い合わせ条件」を載せます。
この形なら、監査で見る枠組みはそろい、現場の速度も落ちにくい設計です。
実務的な選び分けを一言で置くなら、スモールスタートはハイブリッド型ガバナンス×HITL併用が収まりやすいのが利点です。
中央で最低限のルールと証跡を押さえ、現場が実データを仮名加工で扱い、AIが一次処理し、人が閉じる。
この構成だと、精度改善のループと監査対応のループを同時に回せます。
反対に、初手から中央集権×全面内製にすると、承認と作業が詰まりやすく、分散×全面委託にすると、品質と説明責任が分かれます。
営業DXでは、モデルの賢さより運用の詰まりどころが先にボトルネックになります。
どの方式が優れているかではなく、自社のデータ粒度、部門間の役割分担、説明責任の要求水準に対して、どの組み合わせなら止まらず回るかで選ぶのが実務的です。
特に問い合わせ要約、案件分類、次アクション推薦のような現場接点の近いユースケースほど、データ種別、アノテ体制、ガバナンス型は別々に決めず、一つの運用設計として揃えておくほうが後工程で効いてきます。
合成データ利用時の注意点
使いどころの見極め
合成データは、実データの代用品として何にでも使えるわけではありません。
要するに、足りない部分を補う道具としては有効ですが、現場そのものをそのまま再現する前提で置くと精度評価も説明責任も崩れます。
営業やマーケティングの文脈で相性がよいのは、まずデータ不足の補完です。
学習対象の件数が少なく、しかも業務上は見逃したくないクラスがある場合、合成データで分布を補うとモデルが少数クラスを無視しにくくなります。
V7 Labsが示すように、教師データでは1クラスあたり少なくとも1,000サンプルが一つの目安になりますが、実務ではそこまで集まらないカテゴリが先に問題になります。
実際、受注予測でクラス不均衡が強い案件では、失注寸前から逆転受注したような少数パターンを合成データで補ったことがあります。
このとき効いたのは、合成データで学習側の偏りを整える一方、評価側は実データだけの独立セットを残したことでした。
合成側の特徴に引っ張られたモデルは学習中の見た目の指標だけ伸びがちですが、実データだけで切った評価面を別に持っておくと、その場で過学習の兆候が見えます。
合成で件数を増やすこと自体より、実データの物差しを汚さないことのほうが効きます。
次に相性がよいのが、PIIを直接扱いたくない場面です。
個人情報を含む商談メモ、問い合わせ履歴、購買履歴をそのまま学習素材に回すのが難しいとき、元データの構造だけを残して人工的に生成したレコードへ置き換える設計は有力です。
もっとも、合成データなら個人情報リスクがゼロになるわけではありません。
生成元のデータに強い特徴が残っていたり、少数の固有パターンを学習しすぎていたりすると、再識別に近い問題が起きます。
『個人情報保護委員会』が匿名加工情報や仮名加工情報で再識別リスク評価を重視しているのは、見た目上の匿名化だけでは足りないからです。
合成データも発想としては近く、元データとの距離を定義せずに安全とみなすのは危ういです。
もう一つの典型は、レアケースの拡張です。
たとえば、通常は滅多に起きないクレームの急変、特定条件でだけ発生する離脱兆候、商談ログ内の例外的な言い回しなど、実データだけでは十分に学習できないケースがあります。
この種の補完は、生成AIやシミュレーションを使うと作りやすい一方で、作り手の想像力がそのままデータに混ざります。
現場で起きた例外を広げるつもりが、実際には「それらしく見える架空の例外」を増やしてしまうことがあります。
営業DXの領域では、失注理由や次アクション推薦のように文脈依存が強いタスクほど、このズレが後で表面化します。
限界も明確です。
元データに偏りがあれば、その偏りを合成データがなぞるだけでなく、生成過程で増幅することがあります。
品質劣化も見逃せません。
ノイズを減らすつもりで均質なレコードばかり増やすと、現場にある曖昧さや揺れが消え、学習データだけが不自然に整います。
セキュリティ面でも、生成元の取り扱い、プロンプトや中間生成物の保存、外部モデルへの投入経路まで含めて見ないと、表のデータ形式だけ合成に置き換えても安心材料にはなりません。
合成データは「安全だから使う」のではなく、「どのリスクをどこまで下げたいのか」を先に決めて使い分ける対象です。
リスクと対策
合成データ運用で先に押さえたいのは、リスクを技術論だけで閉じないことです。
生成モデルの性能より、どの種データから、どの制約で、何の用途に向けて作ったかが監査では問われます。
Google Cloudのデータガバナンス解説が整理するように、データ管理はポリシー、役割、手順の組み合わせで成立します。
合成データも同じで、生成アルゴリズムだけ管理しても運用は締まりません。
最低限の対策として外せないのは、生成プロセスの記録です。
どの元データを使ったのか、直接PIIを含んでいたのか、匿名加工や仮名加工を経たのか、どのモデルで、どの条件で、どの期間に生成したのか。
この履歴が残っていないと、後から精度劣化や情報漏えい懸念が出たときに切り分けられません。
実務では「学習用CSVがある」だけで終わりがちですが、合成データではCSVの外側にある生成履歴のほうが説明責任を支えます。
用途制限も必要です。
たとえば、少数クラス補完のために作った合成データを、そのまま営業施策の効果測定や経営レポートの母集団分析へ流用すると、判断の前提がずれます。
学習用途では許容できる人工的な補間も、意思決定用途ではノイズになります。
ここで効くのが、データセット単位で「何に使ってよいか」を切ることです。
モデル学習専用、前処理テスト専用、UIデモ専用のようにラベルを分けるだけでも、現場での誤用を抑えられます。
⚠️ Warning
合成データを評価にも使い始めると、数字はきれいでも現場で当たらないモデルが残ります。学習側を人工的に厚くしても、検証側には実データの独立ホールドアウトを置く。この線引きだけで、精度の見誤りが一段減ります。
もう一つの論点は、使用モデルと種データの制約です。
外部の生成モデルを使うなら、入力データの保持方針や学習利用の扱いまで含めて運用設計に落とす必要があります。
社内で閉じた生成基盤を使う場合でも、どのデータ属性を入力禁止にするか、どの粒度まで集約してから生成するかを決めておかないと、PII回避のために合成を選んだ意味が薄れます。
匿名加工情報や仮名加工情報の考え方と同じで、加工したという事実だけでは足りず、どの識別可能性を落とし、どの業務価値を残したかが問われます。
バイアス伝播への対策としては、元データ分布との比較を定期的に入れるのが現実的です。
たとえば受注予測なら、業種、案件規模、流入経路、商談期間のような主要特徴量で、実データと合成データの分布がどこまで乖離しているかを見るだけでも、生成の癖が見えます。
レアケースを増やしたつもりが、特定の属性だけ過剰に増えていれば、モデルはそこを近道として学習します。
合成データの品質問題は、見た目の自然さより、学習に使ったとき何を誤って強調するかで評価したほうが実務に合います。
監査・記録の実務
監査対応では、合成データを「実データではないから軽い」と扱わないことが出発点になります。
説明責任の観点では、元データ台帳に加えて、生成の履歴を持つ拡張プロベナンスが必要です。
どのデータセットから派生したか、前処理で何を削除・変換したか、生成後にどのフィルタを通したか、どのモデル学習ジョブに渡したかまでを線で追える状態にしておくと、後工程の監査で詰まりません。
システム全体の整合性で見ると、合成データだけ別管理にするより、実データ、仮名加工データ、匿名加工データと同じ台帳の中で系譜をつなぐほうが運用が安定します。
再現可能性も監査項目です。
生成時のモデル名、バージョン、パラメータ、乱数シード、前処理コードの版を残しておけば、同じ入力条件で同じ傾向のデータを再生成できます。
ここが曖昧だと、モデルの挙動差が学習ロジックの問題なのか、合成データ生成の揺れなのか判別できません。
営業DXではSalesforceやHubSpotから抽出した元データを別基盤で加工し、BigQueryやSnowflakeに載せて学習へ回す構成も多く、途中の変換が多段になります。
そうした環境では、どの段階で人工生成が入ったかを残しておかないと、障害調査も監査説明も断片化します。
再識別リスク評価も、監査上は避けて通れません。
合成データであっても、元データに近すぎるレコードが混ざっていないか、特定属性の組み合わせで個人や企業を推定できないかを見る必要があります。
年齢、地域、業種、売上規模、特定イベント履歴のような準識別子が重なると、単独では匿名に見えても組み合わせで鋭くなります。
実務では、列ごとのマスキングより、組み合わせたときに一意性が出るかを見るほうが事故を拾えます。
第三者レビューの活用も効果があります。
社内だけで評価すると、生成ロジックを設計したチームが前提を共有しすぎて、危ない近似や不自然な偏りを見落とします。
法務、情報セキュリティ、データサイエンスのいずれか一部門だけで閉じず、少なくとも別ラインのレビューを入れると、用途逸脱や記録漏れが露出します。
体制面では、前のセクションで触れたハイブリッド型ガバナンスと相性がよく、本部が記録様式とレビュー観点を持ち、現場が生成意図と業務文脈を説明する形が回しやすいのが利点です。
監査実務で残しておくと効く項目は、生成元データセットの識別子、生成目的、利用可能範囲、使用禁止用途、生成モデル情報、再生成条件、品質検証結果、再識別リスク評価結果、レビュー承認履歴のセットです。
ここまでそろうと、合成データが単なる便利な代用品ではなく、統制下で扱う正式なデータ資産として位置づけられます。
営業やマーケティングのAI運用では、精度改善の速度と説明責任がぶつかりやすいですが、記録がきちんと残っている環境では、その二つを分けずに回せます。
PoCと本番運用のガバナンス差分
PoCの最小ガバナンス
PoCでは、統制を本番並みに作り込むより、事故を起こしやすい箇所だけ先に締める発想が現実的です。
要するに、短期間で仮説検証を回したい一方で、後から取り返しにくい汚染や権利問題は最初に止めておく、という線引きです。
最小構成として外しにくいのは、評価データの独立確保、データ台帳の暫定版、PII除去ポリシー、そして簡易承認ゲートです。
評価データの独立確保は、PoCで最も軽視されやすい項目ですが、実務ではここが崩れると数字だけ良いモデルが残ります。
直近のセクションでも触れた通り、学習用に手を入れたデータと評価用データが混ざると、PoCの段階では精度が出ているように見えても、本番流量に乗せた瞬間に失速します。
この段階のデータ台帳は、網羅性より追跡可能性を優先します。
どの元データを使ったか、誰が持ち込んだか、何の目的で使うか、加工の有無、外部持ち出しの有無、この5点が追えればPoCとしては最低限の骨格になります。
Salesforceの商談履歴を抽出したのか、HubSpotの問い合わせログなのか、BigQuery上でどのビューを切ったのかが分からない状態でPoCを進めると、再検証も説明も止まります。
PII除去ポリシーも、詳細な社内規程が未整備でも暫定ルールは必要です。
氏名、メールアドレス、電話番号のような直接識別子だけを消せば足りるわけではなく、部署名、地域、案件名、自由記述コメントの組み合わせで個人や企業が浮かぶことがあります。
『個人情報保護委員会』が示す匿名加工情報や仮名加工情報の考え方に沿って、PoCでも「どこまで落とせば学習に使えるか」を先に定義しておくと、後工程で差戻しが増えません。
簡易承認ゲートは、稟議を重くすることが目的ではありません。
データ利用開始前に、事業責任者、法務または個人情報保護の担当、情報セキュリティのどこでYes/Noを出すかを一本化するだけでも、現場の停滞が減ります。
RACIを本格導入する前段として、誰が責任を持って通すのかだけ決めるイメージです。
現場で効いたのは、PoCの時点で評価データを事前に隔離し、再学習には承認ゲートを通す運用を入れたことです。
初期検証では、改善要求が出るたびにログを足して再学習したくなりますが、そのたびに評価セットへ近いパターンが学習側へ流れ込むと、精度改善なのか評価汚染なのか判別できなくなります。
先にホールドアウトを物理的に分け、再学習時に「何を追加し、何を残したか」を承認付きで残す形にしたところ、本番移行後の精度の落ち方が穏やかになりました。
PoCのスピードを落とす施策に見えて、実際には手戻りを減らす効果のほうが大きい運用です。
本番での追加要件
本番に入ると、PoCの暫定統制では足りません。
ここから必要になるのは、個人の善意や記憶に依存しない運用です。
判断の流れ、責任の所在、変更履歴、削除の証跡までを、後から追える形に変える必要があります。
まず追加したいのが正式なRACIです。
データ収集、加工、学習投入、評価、公開停止、削除の各工程で、ResponsibleとAccountableが曖昧だと、障害時に誰も止められません。
たとえばSnowflake上でデータマートを作るチームがResponsible、利用可否の最終判断を事業オーナーかデータオーナーがAccountableとして持つ形にすると、意思決定の滞留が減ります。
法務と情報セキュリティをConsultedに固定し、運用部門をInformedに置くだけでも、差戻しの質が変わります。
承認と監査ログも、PoCの「承認したはず」から、本番では「誰が、いつ、何を見て承認したか」へ進める必要があります。
モデル更新、再学習、評価基準の変更、データソースの追加、PII除去ルールの変更は、すべて履歴化の対象です。
営業DXの現場では、Salesforceの項目変更やHubSpotのフォーム変更が、学習データの意味を静かに変えることがあります。
モデル側だけ版管理しても足りず、データ定義の変更も並べて残さないと、精度変動の原因が追えません。
再学習手順も本番では明文化が要ります。
どういう条件で再学習を起動するのか、誰が承認するのか、評価データは固定か差し替えか、過去モデルへ戻す条件は何かまで定義しておくと、運用は安定します。
PoCでは改善要求に合わせて柔軟に回せたものも、本番ではその柔軟さがドリフトの温床になります。
学習ジョブだけ自動化しても、承認フローと評価基準が未定義なら、単に速く壊れるだけです。
廃棄・削除ルールも、本番で抜けやすい論点です。
使わなくなった学習データ、仮名加工前の中間ファイル、ラベル付け途中のエクスポート、旧モデルの評価セットなど、残り続けるデータほど事故源になります。
匿名加工情報、仮名加工情報のどちらを採るかにかかわらず、保存目的を終えたデータをどう消すか、どの証跡を残すかを決めておかないと、監査で説明が断ち切れます。
セキュリティ運用も、本番では独立した要件になります。
アクセス権の付与・剥奪、マッピング表の分離管理、操作ログの保全、定期的なアクセスレビュー、漏えい時のエスカレーションが必要です。
とくに仮名加工情報を使う構成では、復元可能性を管理で抑える発想になるため、識別符号を持つ領域と分析領域を分け、閲覧権限を切ることが前提になります。
こうした体制は、『IBM』などが整理するデータガバナンスの考え方とも整合します。

What is Data Governance? | IBM
Data governance is the data management discipline that focuses on the quality, security and availability of an organizat
www.ibm.com移行時のチェックリスト
PoCから本番へ移る局面では、技術検証の成功と運用開始の可否を分けて考える必要があります。
モデルが動いたことと、継続運用に耐えることは別問題です。
ここでは移行判断に直結する項目だけを絞って見ます。
まず品質KPIの充足です。
精度、再現率、誤検知率のような指標そのものより、本番で守る閾値が定義され、その値を独立評価データで満たしているかが焦点になります。
PoC中に評価データを隔離していた案件は、この判定がぶれにくくなります。
逆に、改善のたびに評価セットへ寄った運用では、移行会議で数字の意味から議論し直すことになります。
権利確認の完了も、移行時に棚卸しすべき項目です。
社内データだから自由に学習へ回せるわけではなく、利用目的、取得時の説明、委託元との契約条件、外部ツール投入の可否が揃って初めて使えます。
実データ、仮名加工データ、合成データで確認の観点は異なりますが、どの形式でも「利用可能な根拠」が台帳に結びついている状態が必要です。
モデル版管理も見逃せません。
どの学習データ版、どの前処理コード版、どの特徴量定義、どのモデル版が本番に出るのかが一意に追えることが条件です。
BigQueryやSnowflakeのテーブル更新と、学習パイプラインの版がずれたまま移行すると、再現不能な本番モデルが生まれます。
システム全体の整合性で見ると、モデルレジストリだけ整っていても不十分で、データ系譜とセットで管理されているかが問われます。
運用監視とインシデント対応の整備も、移行判定では外せません。
入力分布の変化、推論失敗、権限逸脱、誤学習の兆候、削除漏れが起きたときに、誰が検知し、誰が止め、誰が共有するかまで決まっている必要があります。
これは監視ツールを入れたかどうかより、運用フローが定義されているかの問題です。
移行時に見る観点を整理すると、最低限のチェックは次の通りです。
- 独立した評価データで品質KPIを満たしている
- 学習対象データの権利確認と利用範囲の整理が終わっている
- 学習データ版、前処理版、モデル版の対応関係が記録されている
- 再学習の承認フローとロールバック条件が定義されている
- 監視項目、アラート経路、インシデント時の責任分担が決まっている
- 廃棄・削除対象と保存証跡の扱いが運用に組み込まれている
PoCで通用した「担当者が状況を覚えているから回る」という状態は、本番ではすぐ限界がきます。
ざっくり言うと、移行判定で見るべきなのはモデル単体の賢さではなく、データ、責任、変更、監視の4本線がつながっているかです。
ここがつながっていれば、精度改善の速度を落とさずに統制も維持できます。
よくある失敗と回避策
失敗パターン集
失敗は、精度が出なかったという結果より、どの前提が崩れていたかを追えない状態で起きることが厄介です。
とくにPoCでは、まず動かすことが優先されるため、収集ルール、ラベル定義、評価データの隔離、再学習の承認条件が後ろへ押されがちです。
そのまま本番へ近づくと、精度問題とガバナンス問題が同時に噴き出します。
典型例のひとつが、PoC優先でルールが後回しになるケースです。
営業部門がSalesforceの商談メモ、マーケティング部門がHubSpotのフォーム流入、カスタマーサポートが問い合わせ履歴を持ち寄って、まず分類モデルを作る流れは珍しくありません。
ただ、誰がデータソース追加を承認するのか、どの時点で権利確認を終えるのか、ラベル定義を誰が固定するのかが未整理だと、途中で法務や情報セキュリティの差戻しが入り、PoCで見えていた精度より「そもそも使ってよいデータか」の議論に戻ります。
要するに、技術検証を先に進めても、最小限の統制がないと後工程で止まります。
個人情報の混入も、現場では起き方が地味です。
氏名やメールアドレスのような直接識別子だけでなく、自由記述欄に電話番号、住所、担当者名、個別事情が残っていることがあります。
仮名加工や匿名加工を検討していても、収集段階でデータ分類がされていないと、PII除去前の中間ファイルが学習用バケットへ流れ込みます。
個人情報保護委員会のガイドライン群が示す通り、匿名加工情報や仮名加工情報は「加工したつもり」では成立せず、加工方法と管理の説明が必要です。
単純な列削除だけでは、地域、年代、行動履歴の組み合わせから再識別余地が残る場面もあります。
ラベル基準の曖昧さは、もっとも見落とされやすい失敗です。
同じ「失注理由」でも、営業は競合負けとして扱い、マーケティングはリード品質不足に寄せ、サポートは導入障壁と見なすことがあります。
こうなると、アノテーション担当者が真面目に作業しても、モデルには矛盾した教師信号が入ります。
部門ごとにラベル解釈が割れた案件では、初期のスコアが伸びない理由がモデルではなく、基準書の文章の薄さにありました。
そこで、判定が割れた代表例を毎回持ち寄って定例レビューで潰し込み、「このケースはどちらに入れるか」を具体例ベースでそろえたところ、ラベルのばらつきが減り、改善の方向が見えるようになりました。
抽象語だけの基準書より、境界事例の共有のほうが効きます。
重複データの放置も、PoCでは見逃されがちです。
Salesforceの活動履歴とHubSpotの送信ログ、CSVエクスポートの再取り込み、チケットシステムからの複製で、同一内容が別レコードとして混ざります。
この状態で学習すると、特定パターンが不自然に強く学習され、評価時も似たデータが混ざって見かけの成績が上振れします。
重複は完全一致だけでなく、軽微な表記差を含む類似データとして入るため、単純なキー重複チェックだけでは足りません。
重複排除と類似検知を定例運用にし、いつ何を除外したかを監査ログで追える形にしておかないと、再現性が崩れます。
運用後の再学習が未整備なまま始まる失敗も多く見ます。
PoCでは担当者判断で学習データを差し替え、閾値を動かし、ラベルを修正できても、本番ではそれが事故の入口になります。
入力分布が変わった、フォーム項目が変わった、商材が増えたといった変化が起きても、何をトリガーに再学習するのか、誰が承認するのか、旧モデルへ戻す条件は何かが決まっていないと、改善のつもりで品質を崩します。
システム全体の整合性で見ると、学習ジョブの自動化より先に、変更管理の流れを閉じる必要があります。
評価データ汚染は、数字だけ見ると発見が遅れる失敗です。
テストセットの一部が改善会議で共有され、それを前提に前処理や特徴量を調整してしまうと、独立評価ではなくなります。
あるいは、学習用データと評価用データの間に重複や類似案件が残っていて、未見データに対する性能だと誤認することもあります。
IBMが整理するデータガバナンスの考え方でも、評価に使うデータの独立性は説明責任の土台です。
評価用データは事前に隔離し、アクセス権を切り、用途を限定して初めて意味を持ちます。
回避策チェックリスト
ここで有効なのは、壮大な統制ではなく、先に壊れやすい点だけを固定することです。
PoCでも本番でも共通して効くのは、最小ガバナンスを先行させる設計です。
具体的には、データソース、利用目的、加工有無、責任者、承認者を台帳にまとめ、追加や変更が入ったら更新する運用を先に置きます。
RACIの考え方でResponsibleとAccountableを切ると、収集可否や公開可否の判断が宙に浮きません。
現場スピードを落とさずに差戻しを減らすなら、最初に決めるべきは細則より責任線です。
個人情報の混入に対しては、収集前の分類が起点になります。
実データをそのまま運ぶのではなく、PIIを含む列、自由記述、識別子に近い属性を分け、どこで除去し、どこで仮名化し、どこまで匿名化を目指すかを加工方針として明文化します。
社内分析向けに系列性を残すなら仮名加工情報、外部共有や二次利用まで見込むなら匿名加工情報というように、利用形態に合わせて前処理の深さを変えるのが筋です。
加工ルールを文書化していないと、同じデータでも担当者ごとに処理が変わり、監査にも再現にも耐えません。
ラベル品質を安定させるには、ルーブリックと例示をセットで持つことが欠かせません。
定義文だけで終えず、迷いやすいケース、境界ケース、除外ケースを代表例として並べます。
そのうえでダブルアノテーションを入れ、判定が割れた箇所は定期レビューで基準書へ戻します。
実務では、アノテーターの能力差より、基準書の曖昧さがノイズ源になる場面が多いです。
部門横断で解釈がぶれる案件ほど、レビュー会で代表例を見ながら言葉をそろえる運用が効きます。
重複データへの対策は、単発のクレンジングでは足りません。
完全一致の排除に加えて、件名、本文、日時、顧客属性の組み合わせで類似検知を回し、定例作業に落とし込みます。
さらに、除外・統合・保留の判断を監査ログへ残しておくと、後から「なぜこの件が学習に入っていないか」を追えます。
PoCの段階でこのログがないと、精度差の説明が担当者の記憶頼みになります。
再学習については、技術条件ではなく運用条件まで定義しておくと崩れません。
たとえば、入力分布の変化、ラベル不一致の増加、業務ルール変更、データソース追加を再学習トリガーに置き、その発火後に誰が承認し、どの評価セットで判定し、どの条件ならロールバックするかまで先に決めます。
モデル改善を継続するなら、自由に学習し直せる状態ではなく、承認ゲートを通って更新される状態のほうが結果として安定します。
評価データ汚染の回避では、事前の隔離確保とアクセス制御が中核です。
評価用データは学習用データと保管場所を分け、閲覧できる役割を限定し、改善会議で個票を見せない運用にします。
加えて、学習前に重複・類似チェックを通して、評価セットと訓練セットの近接度を下げます。
これを後追いでやると、過去のスコアの意味が崩れるため、最初から「触れない評価データ」を明確に切っておくほうが運用が安定します。
実務で使うなら、確認項目は次の粒度まで落ちていると機能します。
- データソース、利用目的、責任者、承認者が台帳でひも付いている
- 収集前にPIIを含む項目が分類され、除去・仮名化・匿名化の方針が決まっている
- ラベル基準に定義文だけでなく代表例と境界例が含まれている
- ダブルアノテーションと定例レビューの流れが運用に入っている
- 完全一致と類似データの両方を対象に重複排除を回している
- 重複除外、ラベル変更、前処理変更の履歴が監査ログに残っている
- 再学習のトリガー、承認者、評価手順、ロールバック条件が定義されている
- 評価データが学習データから隔離され、アクセス権が分離されている
こうした対策は、一見すると手間に見えます。
ただ、AI開発ではデータ準備と強化に工数の大半が乗ることが多く、後からやり直すほど損失が膨らみます。
ざっくり言うと、失敗を防ぐコツは、高度な仕組みを並べることではなく、混ざる、ぶれる、重なる、漏れる、勝手に更新されるという典型的な壊れ方を先回りで塞ぐことです。
まとめ:まずはデータ台帳と利用ルールの整備から始める
高品質なデータは、収集や前処理だけでは持続しません。
運用に耐える形にするには、ガバナンスと一体で回し始める必要があります。
実務では、台帳、評価データの隔離、最小限のRACIを先に置くと、その後の可否判断や差戻しが減り、意思決定の流れが目に見えて整います。
着手点として優先したいのは、学習候補データの棚卸し表を作り、PII、機密、著作権の有無を分類すること、利用申請フローと承認責任者を決めること、評価データを独立して確保することです。
関係部門は事業、情シス、セキュリティ、法務、監査の5者で十分で、最低限の成果物はデータ台帳初版、承認フロー図、アノテ基準1枚、品質KPIシートから始めれば前に進めます。
次に見るべき論点は、評価方法とKPI設計をどう置くか、そして導入ROIをどう測るかです。
ITコンサルティングファーム出身。営業DX推進プロジェクトをリードし、SFA/CRM/MAの統合設計とAI活用による営業プロセス自動化を専門としています。
関連記事
営業DXの進め方完全ガイド|失敗する4大原因と成功する4ステップ
営業DXの進め方完全ガイド|失敗する4大原因と成功する4ステップ
営業DXは、ツールを入れれば進む領域ではなく、定着まで設計して初めて成果につながる分野です。PwC Japanの2024年調査では十分な成果を出している企業は約9.2%にとどまり、INDUSTRIAL-Xの同年調査でも導入後に運用・定着できていない企業が22.3%に達しています。
SFA活用事例7選|営業成果の共通点と再現条件
SFA活用事例7選|営業成果の共通点と再現条件
SFAは、導入しただけでは営業成果につながりません。営業現場では入力が増えて疲弊し、そのまま使われなくなる流れが繰り返されがちですが、実際に運用してみると、入力項目を絞り込み、マネージャーが会議でそのデータを使い切る形までそろったときに定着率は一気に変わります。
営業DXの進め方|成功事例とツール活用のポイント
営業DXの進め方|成功事例とツール活用のポイント
営業DXは、SFA(営業支援ツール:商談・活動・案件管理を可視化するツール)やCRM(顧客関係管理:顧客情報と接点履歴を一元管理する仕組み)を入れれば前に進む話ではありません。現場では、最初に決めるべき入力項目と運用ルール、そして責任者が曖昧なまま導入が始まると、データが揃わず定着も止まりがちです。
営業DXとは?デジタル化との違いと進め方
営業DXとは?デジタル化との違いと進め方
営業DXは、紙をExcelに置き換えたりSFAを入れたりして終わる話ではありません。データとデジタル技術を使って、営業プロセスそのものと役割分担、KPI運用まで組み替え、受注の再現性を上げていく取り組みです。